контакты
Для всех:
- Кейсы живые и модельные
- Тарифы
- API
- Регистрация и ВХОД
- Контакты
- Significance: A/B, mass A/B
Кейсы увеличения конверсии на модели посетителя
Почему "наивное" предположение в MVT о независимости факторов не работает
Роботный трафик, очень слабая зависимость CR (*1.2), 1 тест на 3^15 лендингах
Роботный трафик, слабая зависимость CR (*1.333), 10 тестов на 3^12 лендингах
Роботный трафик, средняя зависимость CR (*1.5), 100 тестов на 9^4 лендингах
Роботный трафик, средняя зависимость CR (*1.5), 100 тестов на 3^9 лендингах
Роботный трафик, очень слабая зависимость CR (*1.2), 100 тестов на 6^6 лендингах
Роботный трафик, слабая зависимость CR (*1.333), 100 тестов на 6^6 лендингах
Роботный трафик, средняя зависимость CR (*1.5), 100 тестов на 6^6 лендингах
Роботный трафик, сильная зависимость CR (*2), 100 тестов на 6^6 лендингах
Роботный трафик, сильная зависимость CR (*2), 10 тестов на 6^9 лендингах
Описание работы с роботным трафиком и моделями поведения
Роботный трафик, сильная зависимость CR (*2), 10 тестов на 6^9 лендингах
Модель пользователя здесь предполагает сильную зависимость конверсии от наличия набора эффективных факторов. Возьмем 6 факторов по 9 вариантов значений у каждого = 9^6= 531441 уникальных лендингов. ПЯТЬСОТ ТЫСЯЧ ЛЕНДИНГОВ.
Пусть в том случае, когда мы угадали все-все 6 заветных значений, посетитель поражен в самое сердце :) и такая комбинация имеет конверсию 100%.
Если же мы ошиблись в значении одного фактора, то конверсия падает в два раза (50%). Если две ошибки - еще в два раза (25%) и т.д.
0,0,0,0,0,0 CR=1 0,0,0,0,0,* CR=0.5 - один не угадали - в два раза хуже 0,0,0,0,*,* CR=0.25 - два не угадали - еще в два раза хуже .. угадано конверсия 6 100.00% 5 50.00% 4 25.00% 3 12.50% 2 6.25% 1 3.13%
Однако, задача с одной старшей комбинацией может быть решена и наивным методом в предположении о независимости факторов - при случайном розыгрыше значений совпадения с нулем будут давать плюс в конверсию, если не совпало - конверсия ниже. Такая задача слишком проста.
Поэтому для усложения модели возьмем 9 старших комбинаций, которые не пересекаются (шесть раз одинаковые значения: 0,1,..8), вероятность берется максимальной по всем сравнениям со всеми старшими комбинациями - эту задачу не решить наивным методом.
Модель хорошая? Кроме того, для подлива данных 20% трафика угадывалка направляет на случайную генерацию, на проверку кандидатов - ничего.
Запускается десять одинаковых экспериментов по 10 тыс. просмотров. Раньше или позже пять копий выходят на конверсию 75%, и еще пять - на конверсию 50%:
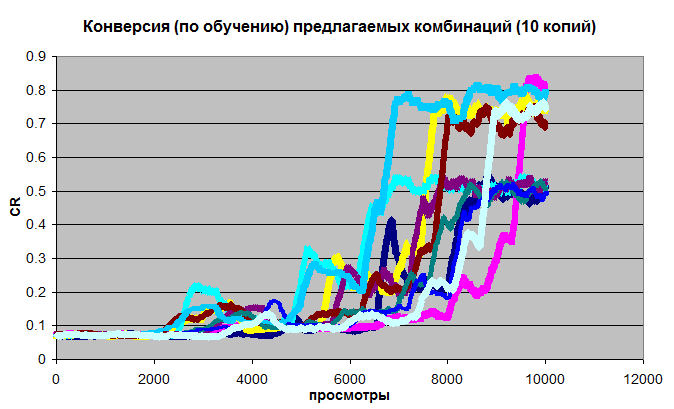
Это очень хорошо (с учетом того, что теоретический максимум CR здесь 82%, т.к. 20% трафика - это рандом с конверсией около 7.3%)
Но ведь это конверсия по обучению, которое обязано проверять не только самые лучшие варианты, но захватывать и плохие. В процессе эксперимента угадывалка постоянно готовит кандидатов на проверку, пересчитывает их качество с учетом новых данных от обучения.
Но мы знаем, какие именно комбинации действительно самые лучшие, и на графике ниже показана позиция первой самой лучшей комбинации в пуле кандидатов при сортировке по убыванию качества:
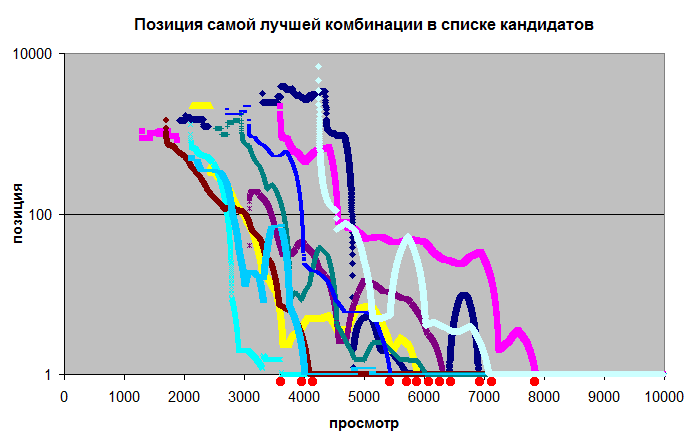
Там, где позиция становится равной единице - система посчитала, что действительно лучшая комбинация имеет максимальное качество, угадала ее правильно. Видно, что первые комбинации угаданы около 3.5-4 тыс. простотров, а последний угадан на 8 тыс. просмотров.
Т.е., задача решена в 10 случаях из 10.
контакты