контакты
Для всех:
- Кейсы живые и модельные
- Тарифы
- API
- Регистрация и ВХОД
- Контакты
- Significance: A/B, mass A/B
Кейсы увеличения конверсии на модели посетителя
Почему "наивное" предположение в MVT о независимости факторов не работает
Роботный трафик, очень слабая зависимость CR (*1.2), 1 тест на 3^15 лендингах
Роботный трафик, слабая зависимость CR (*1.333), 10 тестов на 3^12 лендингах
Роботный трафик, средняя зависимость CR (*1.5), 100 тестов на 9^4 лендингах
Роботный трафик, средняя зависимость CR (*1.5), 100 тестов на 3^9 лендингах
Роботный трафик, очень слабая зависимость CR (*1.2), 100 тестов на 6^6 лендингах
Роботный трафик, слабая зависимость CR (*1.333), 100 тестов на 6^6 лендингах
Роботный трафик, средняя зависимость CR (*1.5), 100 тестов на 6^6 лендингах
Роботный трафик, сильная зависимость CR (*2), 100 тестов на 6^6 лендингах
Роботный трафик, сильная зависимость CR (*2), 10 тестов на 6^9 лендингах
Описание работы с роботным трафиком и моделями поведения
Роботный трафик, средняя зависимость CR (*1.5), 100 тестов на 6^6 лендингах
В предыдущих экспериментах мы использовали сильное изменение конверсии при каждой дополнительной ошибке - вдвое. Однако, чем сильнее эта зависимость, тем легче угадать правильный лендинг. Конечно, и такие сильные зависимости могут встречаться в жизни, но желательно иметь и решение, которое работало бы и при более слабых зависимостях. Тестирование улучшенного решения тут представлено для более слабой зависимости - при каждой ошибке относительно одной из "лучших" комбинаций конверсия падает в 1.5 раза, а не в 2.
Параметры модели пользователя:
- Используется 6 факторов по 6 вариантов значений у каждого = 6^6= 46656 уникальных лендингов.
- Максимальная конверсия 50% у любой из "лучших" комбинаций, всего их 6 непересекающихся (000000, 111111, .. 555555) - для усложнения задачи
- При каждой ошибке относительно одной из "лучших" комбинаций конверсия падает в 1.5 раза.
- При частичном совпадении комбинации значений с несколькими "лучшими" - используется максимальная конверсия.
- Запускается 100 экспериментов в одинаковых условиях.
Варианты конверсии для разных частичных совпадений выглядят так:
0,0,0,0,0,0 CR=50.00% - одна из набора "лучших" комбинаций 0,0,0,0,0,* CR=33.33% - один не угадали - в 1.5 раза хуже предыдущей 0,0,0,0,*,* CR=22.22% - два не угадали - еще в 1.5 раза хуже предыдущей, т.д. 0,0,0,*,*,* CR=14.81% 0,0,*,*,*,* CR=9.88% 0,*,*,*,*,* CR=6.58%
Т.к. мы иcпользуем не очень большое число значений, при случайном розыгрыше значений средняя конверсия будет 12% за счет случайного выпадения пар, троек, т.д. Наша цель - угадать одну из самых лучших комбинаций.
Задача с одной лучшей комбинацией может быть решена и наивным методом в предположении о независимости факторов - при случайном розыгрыше значений совпадения с нулем будут давать плюс в конверсию, если не совпало - конверсия ниже. Такая задача слишком проста. Поэтому для усложения модели возьмем 6 старших комбинаций, которые не пересекаются (шесть раз одинаковые значения: 0,1,..5), вероятность берется максимальной по всем сравнениям со всеми старшими комбинациями - эту задачу не решить наивным методом.
Запускается сто одинаковых экспериментов.
Конверсия, которая соответствует предложенным системой лендингам, в ходе тестирования увеличивается так:
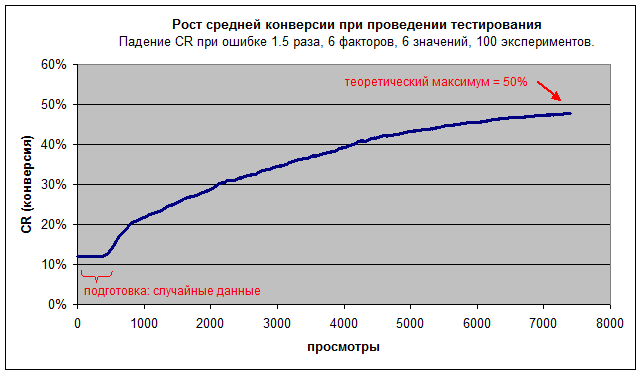
Однако, все показанные системой лендинги включают в себя и обучение, которое обязано пробовать не только самые лучшие варианты, но захватывать и плохие. Конверсия же самого лучшего варианта, без обучения, показана здесь (среднее по 100 экспериментам):
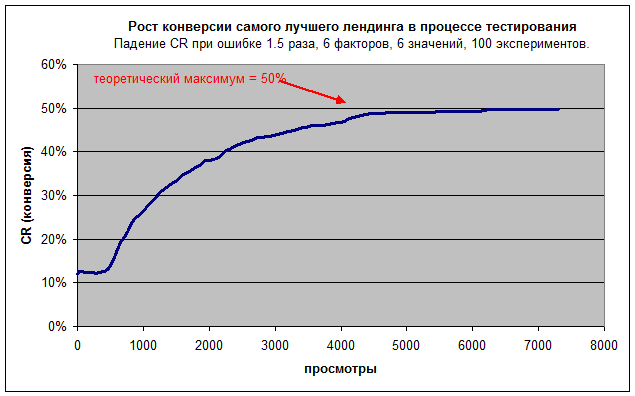
Т.к. скрипт, моделирующий действия пользователя, знает набор "лучших" лендингов, мы можем изобразить процесс угадывания их. Каждая точка соответствует угадыванию лучшего лендинга в одном эксперименте:
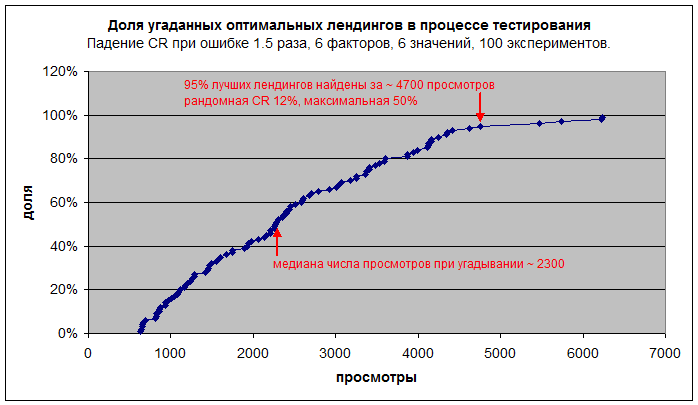
В итоге за ~ 7000 просмотров найдено 99% лучших комбинаций факторов, 95% их найдено за ~ 4700 просмотров, в среднем по всем экспериментам потребовалось ~ 2400 просмотров для нахождения оптимального лендинга.
Задача решена в 99 случаях из 100 за ~ 7000 просмотров.
контакты